
Consider the following problem :

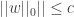
Where c is a user-specified and constant number. The function f(w) here maybe the empirical risk or log likelihood of the training samples. The constraint limits the scope of the parameters space in order to prevent overfitting. According to my best knowledge there are three main ways to obtain sparse solutions for the optimization problem (1)
- Enforcing the parameter w to be nonegative
I think we have a basic fact in optimization which states that the optimal solutions lie on the boundary of the feasible region. We have two examples for this case:
A commonly typical example is SVM. In the dual form of SVM, the Langrange multipliers are nonnegative. Therefore the solutions tends to sparse. In this case the non-zero solutions are called support-vectors.
Another example that I meet in my graduation thesis is the Kullback-Leibler Importance Estimation Procedure (KLIEP) which appeared in []. In this work, authors represented the importance weights
. Based on the data, we have to estimate the parameters
such that KL-divergence from the density function of test data
to the density function of training data multiplied with importance weights
is minimized. We will obtain a constraints convex optimization which can be solved by projected gradient ascent. The constraint
ensure that the optimal solutions contain lot of zero coefficients.
- Adding a regluarization term
In order to obtain sparse solutions we can add a term in the form
in the original objective function with
, then we have:

Where C is the regularization parameter .
According to Bayesian statistics, if f(w) here is log-likehood, the optimization problem (2) is equivalent with maximum a posterior. We place Laplace distribution on the parameter w in the case of p=1, and a zero mean and an identify covariance matrix Gaussian distribution in the case of p=2. The paramaters in these distributions will lead to the appearance of parameter C, so C may be called as the hyperparameter. How to adopt a possibly optimal paramter C will be discussed in the next post.
p=1 is a popular choice, but we should be care since the overall function is not differentiable at some
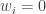
Eg: L1-SVM, Lasso,..
 nhưng với qbit thì ta có :
nhưng với qbit thì ta có :  tức là ta có thể lưu trữ dữ liệu đa bit. Với các giới hạn vật lý, ta không thể có tình trạng là một điểm bất kì trong
tức là ta có thể lưu trữ dữ liệu đa bit. Với các giới hạn vật lý, ta không thể có tình trạng là một điểm bất kì trong  .Điểm khác biệt giữa bit bình thường và quantum bit nằm ở 1 khái niệm trong vật lý là entanglement.
.Điểm khác biệt giữa bit bình thường và quantum bit nằm ở 1 khái niệm trong vật lý là entanglement.

